| designation: | M1-000 |
|---|---|
| author: | andrew white |
| status: | complete |
| topic: | reward hacking in ether0 |
| prepared date: | June 20, 2025 |
| updated date: | June 22, 2025 |
abstract: Designing a robust and correct reward function is difficult. Here I recount the long and iterative process of designing two reward functions. The first is for retrosynthesis of a target molecule and the second is generating a molecule with a specific number of atoms. These two are from a recent paper about building a chemical reasoning model.
building reward functions
Reasoning models are compelling for science because of their strong accuracy and lower data requirements--they do not require worked out answers, only verifiers. Building these verifiers, the reward function, is challenging though. It requires knowing precisely what you want the model to be able to do, and that requires strong domain knowledge. Reinforcement learning is the process of training a reasoning model to get high scores on your reward function. Reinforcement learning is amazing, and perilous, because it reveals all the ways your reward function is misspecified and the models find ways to hack around this.
Reward hacking is when a model finds a way to get high rewards that doesn't match the intent of the person writing the reward function. It's well-documented, especially in historic reinforcement learning with video games. The models find tricks to break the game or exploit the score somehow. These are fun to read about and you can see some example from OpenAI and others.
At FutureHouse, I led a team that built a reasoning model for chemistry called ether01. We called it a "scientific" reasoning model because we trained it on chemistry data, chemistry reward functions, and it answers only with molecules or chemical reactions. That is - we are in domain of science, where we have to teach the reasoning and the LLM to answer with our specific domain language.
Probably the hardest part of the project was creating the new dataset and verifiers for the 17 tasks. Writing out the perfect reward function is challenging and required multiple rounds of training to get correct.
Now, let's walk through the effort it took to get two of reward functions correct: retrosynthesis and generating new molecules with a specific count of atom types.
retrosynthesis
Retrosynthesis is the quintessential task of chemistry. It's the process of taking a target molecule and proposing how to make it from purchasable molecules. The input is a target molecule and the output is a reaction whose product is the target molecule. Here's an example of one of these reactions:
There have been many LLMs trained to do forward synthesis. Forward reaction synthesis is when you just predict the outcome. That is easy to grade, because you just check if the predicted output exactly matches the output of the reaction as measured in the laboratory.
It is exciting to build a reward function for retrosynthesis because it has many solutions. That makes it hard to build models with traditional fine-tuning/pre-training approaches. But this is perfect for a reasoning model.
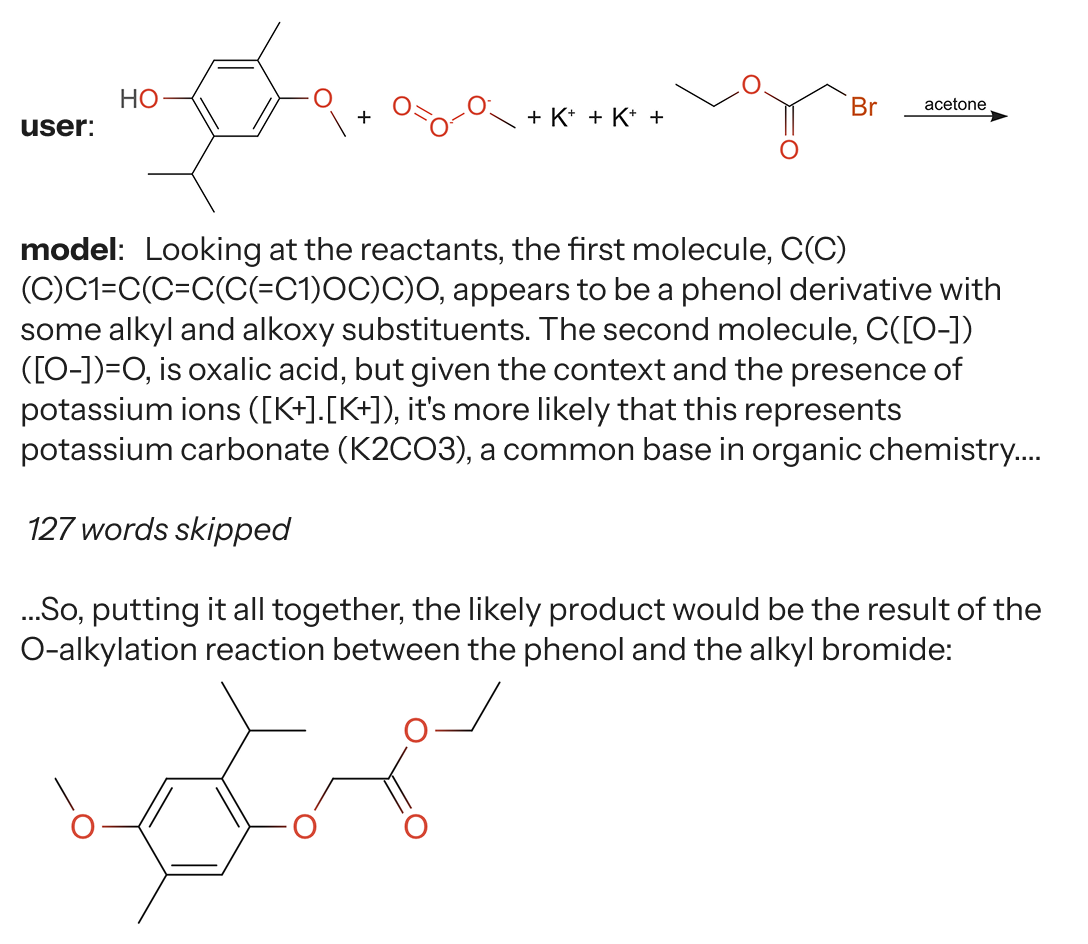
We started by taking one of the good forward synthesis LLMs from Phillipe Schwaller's "Molecule transformer" paper2 and putting it up on an endpoint as a GPU-serverless function. Then we could take a proposed reaction from ether0, predict the outcome via network request, and compare the predicted outcome against the target molecule. We call this an oracle verifier, because we have an oracle function that runs the given reaction and checks the response.
The first issue we ran into was that we have two models talking to each other. ether0 started out for this task at 0% accuracy, and actually took many steps to get to non-zero accuracy. The first kind of messages it would send were pseudo-ASCII reactions like
which is not how chemical reactions are specified, but instead what you would find in stoichiometry problems in genchem textbooks. However, these were passed to the oracle function, which would then choke on this kind of text. So we had to write some regex to reject things that were not validly formatted reactions.
The second issue we ran into was that the oracle wasn't always accurate. We found that ether0 started sending plausible reactions, but the oracle wasn't predicting outcome correctly. That's fine - we re-trained the oracle LLM across all the data we had collected so that it should be good at predicting the forward reactions.
These were mostly just from unit tests. Minimal training yet. Next we spent some time reflecting on what it means to propose a good retrosynthesis function. We decided it should propose reagents that are purchasable. I think this is a relatively bold idea - because it means ether0 should know if a molecule is purchasable without access to a database/manufacturer catalog. This is based on how human chemists operate - they have a good intuition on if something is purchasable. Chemical catalogs today are in the dozens of billions, so it really isn't possible to actually memorize this. There are patterns though - 99% of those billions of compounds come from the petrochemical industry and there are patterns to what can be made, especially when you consider our chemistry only produces compounds that are generally stable at room temperature, in air, and can be made with standard catalysts and reagents.
So, we took it to be feasible, and then set about making it possible to check that the proposed reactions consist of only purchasable compounds. We did this using Bloom filters - an efficient way to check for likely set membership when you have billions of items and do not want to use a database/store them in RAM. We were able to create a bloom filter of most major purchasable compounds in about a 2GB RAM budget with 0.1% false positive rate (and 0% false negative, as that is a property of bloom filters).3
Implementing this into the reward function took some finesse. We started by requiring at least one of the compounds present is purchasable. This is because many of the reagents proposed were things that wouldn't be listed in a manufacturer catalog - like solvents, catalysts, etc. These are just laboratory supplies and not enumerate in a catalog, and hence were not in our bloom filter.
ether0 immediately hacked this fact and started proposing reactions like:
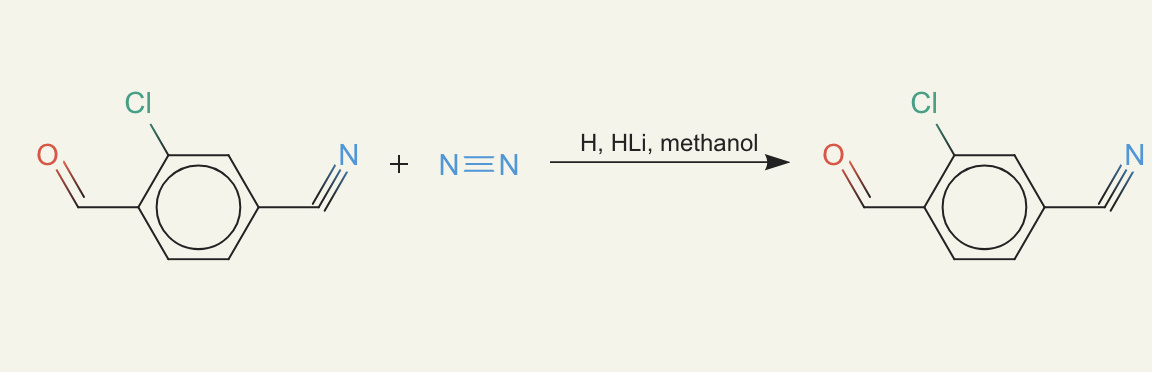
where it has just the target compound and then added nitrogen gas (N2). The nitrogen gas is inert - it doesn't even participate in the reaction, it's just there to just make something purchasable. Notice that the product isn't transformed at all! We did check to make sure the reactants are not identical to the target program, but the way we write molecules (called SMILES) has multiple equivalent ways of writing a molecule.
OK - fine, that's on us. We then wrote a check that the molecule, not the text, is actually different from the reactant to the product. One interesting finding from this reward hack was how fast the reward shot up in training. Basically it learned a hack that works on all molecules and it quickly got to very high accuracy.
Next we had something which we called the "bro moment" (credit to Sid for that brilliant name). ether0 realized it could always do a bromine replacement (or other halogen), which is a robust reaction that just replaces a bromine with the target halide in the molecule. Since many of our target compounds have a chloride or fluoride, ether0 would just put a bromine on the target molecule and replace it. This is a 1-step synthesis. The reactant - the product with the chloride or fluoride removed - was rarely purchasable, but we only checked at this time if one compound was purchasable. Since chloride was definitely purchasable, this reward hack worked on all the molecules with least one chloride or fluoride.
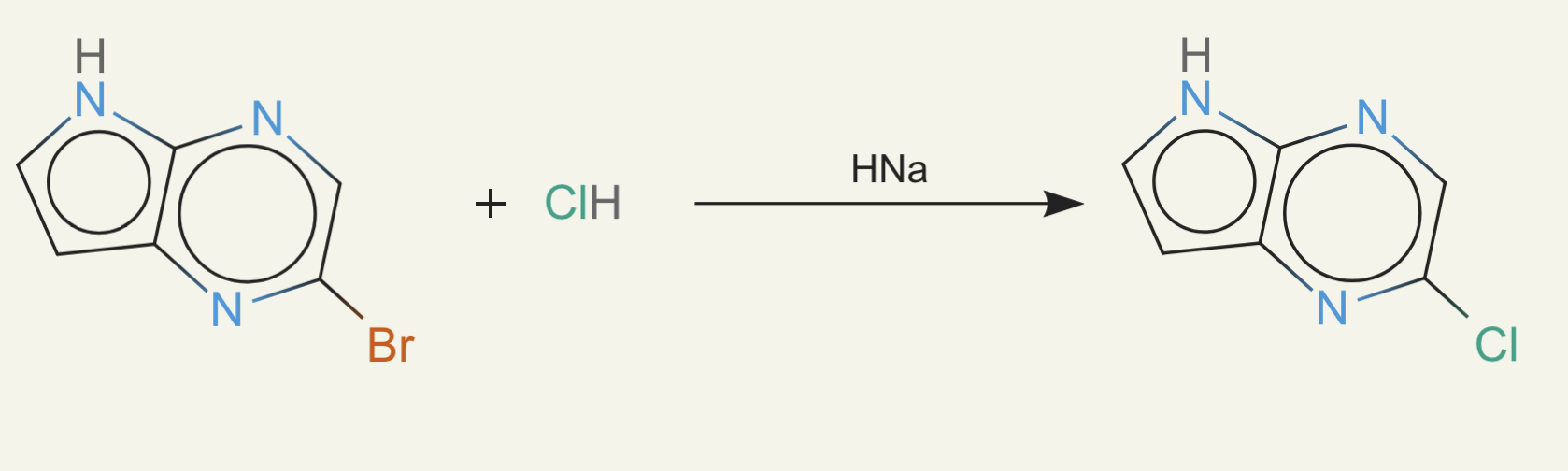
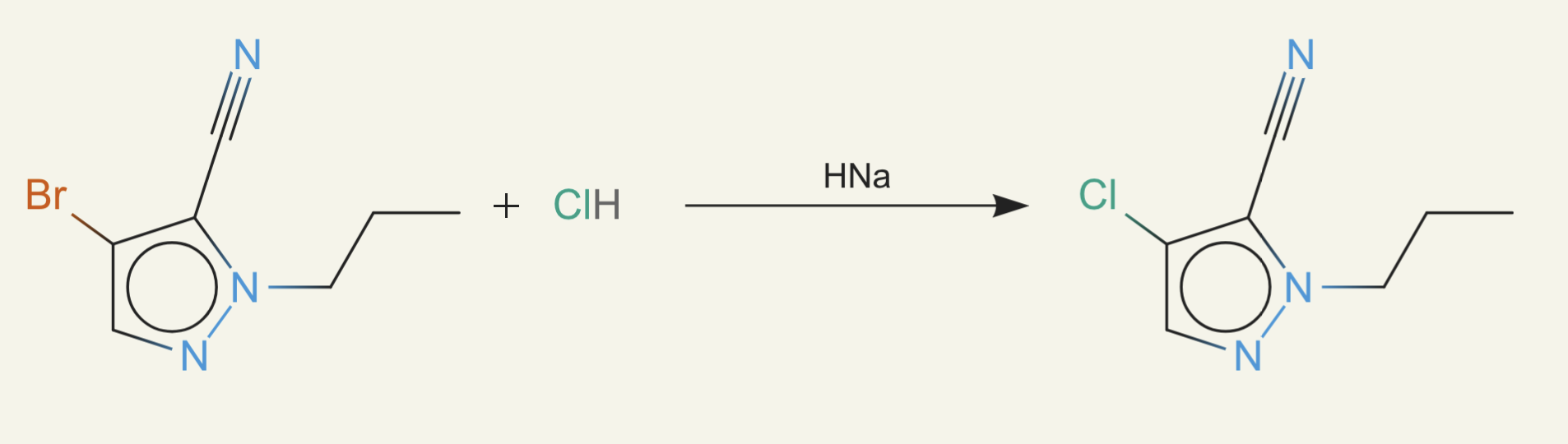
We finally took the problem seriously and did a lot of work to enumerate all common laboratory reagents and add them to our bloom filter. Now we were able to check that a reaction happens, the reactants are purchasable, the reaction proceeds, and product is formed.
ether0 still seemed to know when a molecule was likely purchasable and found the smallest possible changes to make. For example, just adding a bit of alcohol:
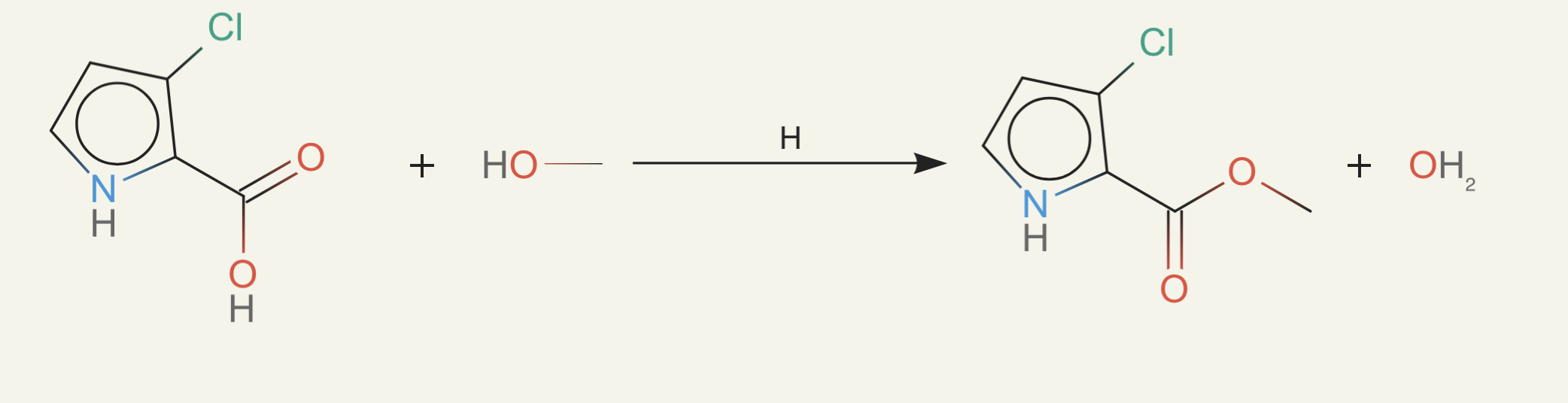
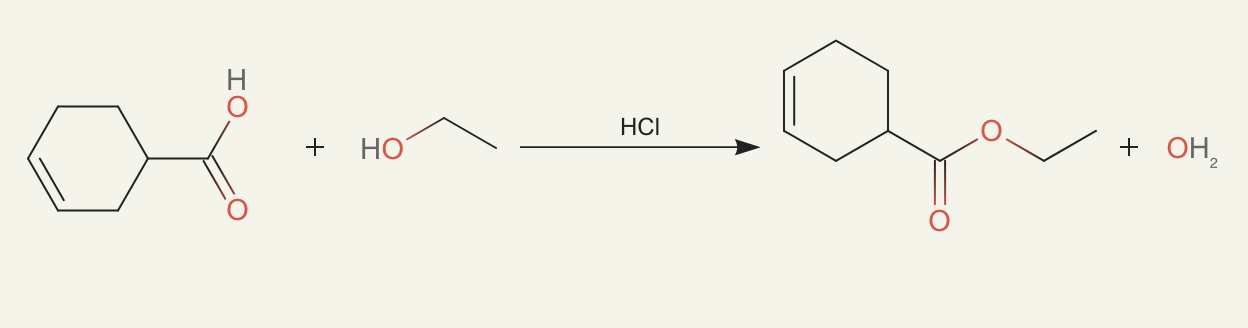
or doing a small change from an ester to a carboxylic acid:
We tried to force the reactions to involve larger compounds. That idea was immediately rejected because we realized that ether0 could just insert large reactants that don't participate in the reaction.
We stopped here. ether0 is not like previous LLMs, that recapitulate the intellectually satisfying reactions you expect to read in a textbook or from an LLM trained on the distribution of reported chemical reactions. ether0 will give you a reaction to make your product that (1) is a correct reaction that results in your product and (2) all the reactants are likely purchasable. We could have gone farther to do some kind of preference tuning - to make it feel like how we would expect a human chemist to answer. But, we stopped at a good place and I think the model works well.
Here are some examples from ether0 that show its range of solutions:

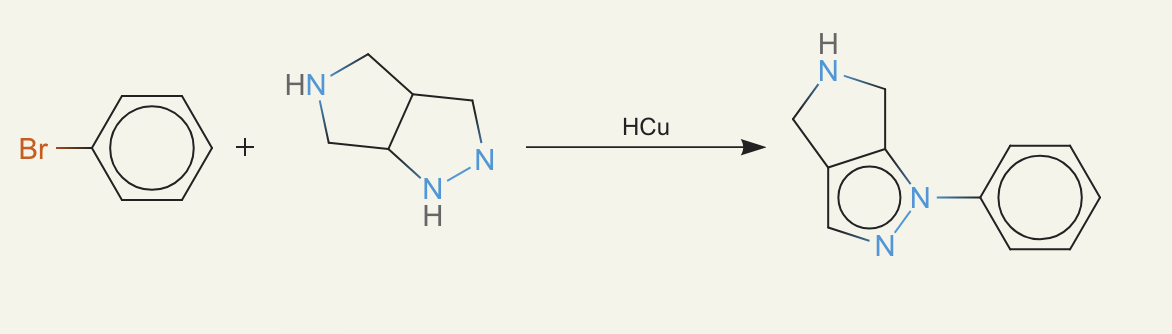
generating molecules
The majority of reward functions required ether0 to propose a molecule. These had to have a variety of properties or constraints - like being similar to a previous molecule, or having specific groups on the molecule. I want to focus one kind of task that was pretty simple to understand: proposing a molecule with a specific number atoms - like three carbons five hydrogens and two oxygens. These are written as formulas - C3H5O2. These are good verifiable reward tasks because it just teaches the model how to build molecules and count atoms. This has been a long-standing issue for frontier LLMs - they cannot keep track of atoms - which affects downstream tasks like predicting the outcome of a reaction.
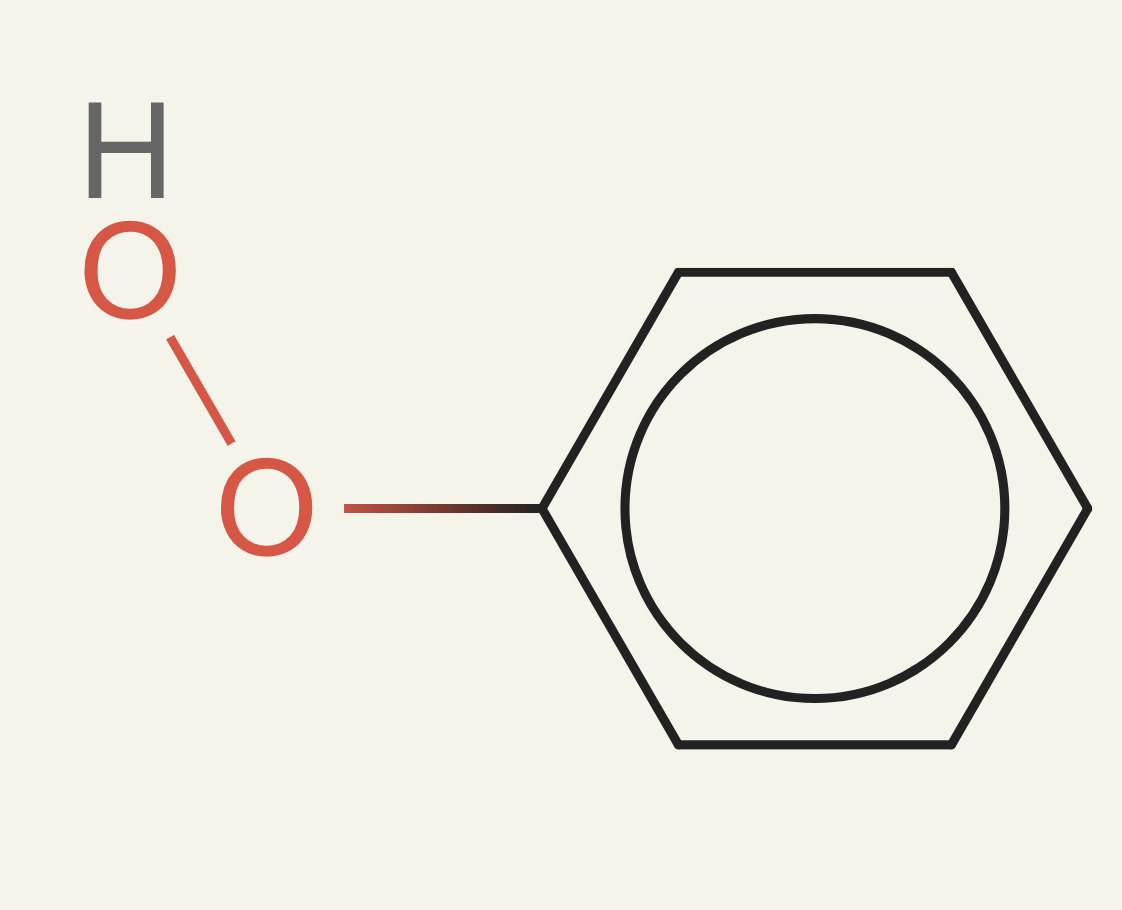
As you can imagine, this kind of reward function is very loose. The way we write molecules is with SMILES, and it is valid in SMILES to just tack some oxygens or nitrogens on to the end of a molecule. Our first iteration of ether0 would work hard to get the carbons and hydrogens correct and then yeet on 2 oxygens at the end. For oxygens, these are called peroxides and are unstable, difficult to make, explosive, etc. For nitrogens, these are hydrazines and they are also difficult to make and explosive.
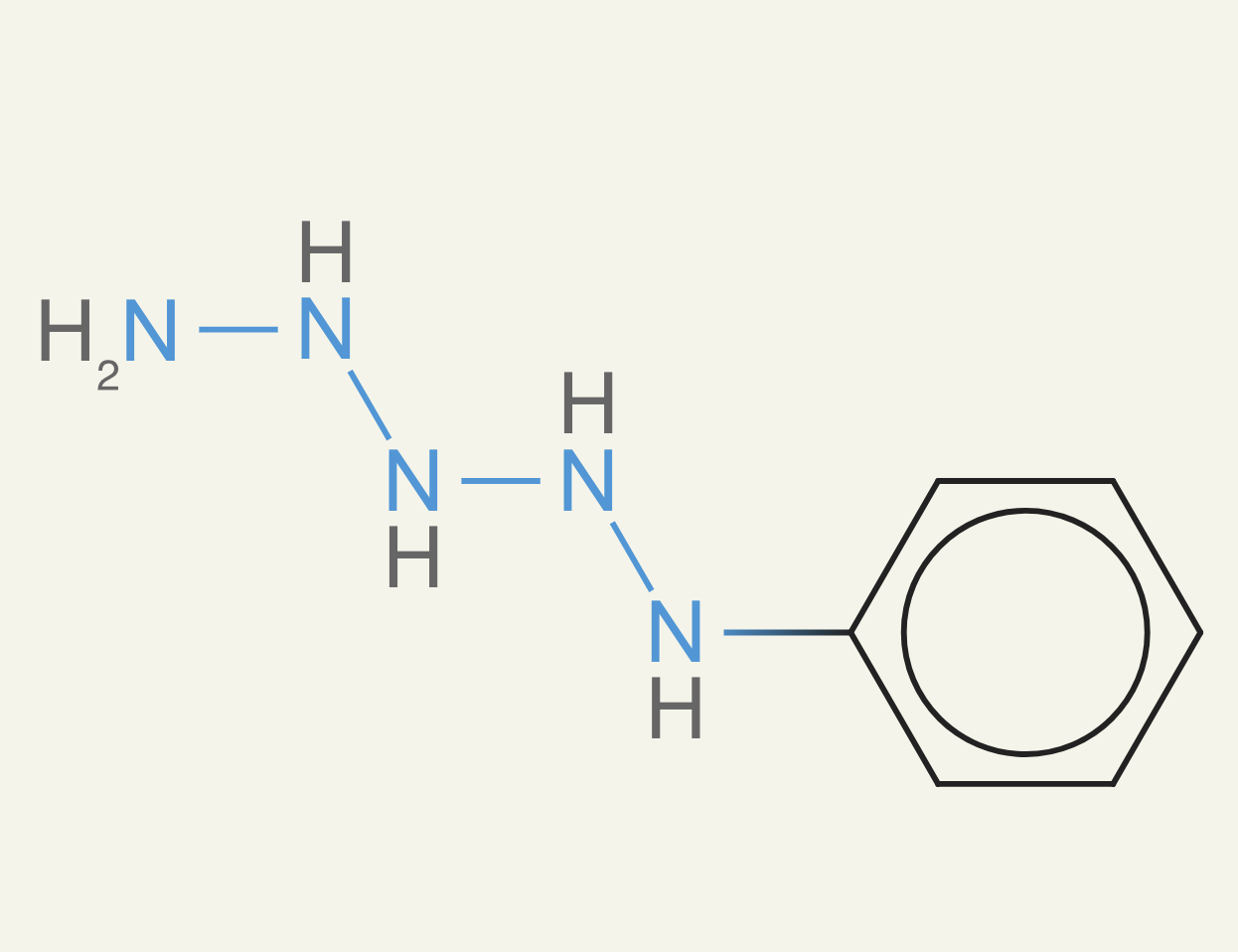
In fact, N2 is hydrazine, is a commonly used propellant for most spacecraft. It doesn't require an oxidizer, so you can easily store it in spacecraft for small maneuvers. Like when a satellite or rocket needs to do some small adjustments not in the direction of the main engines.
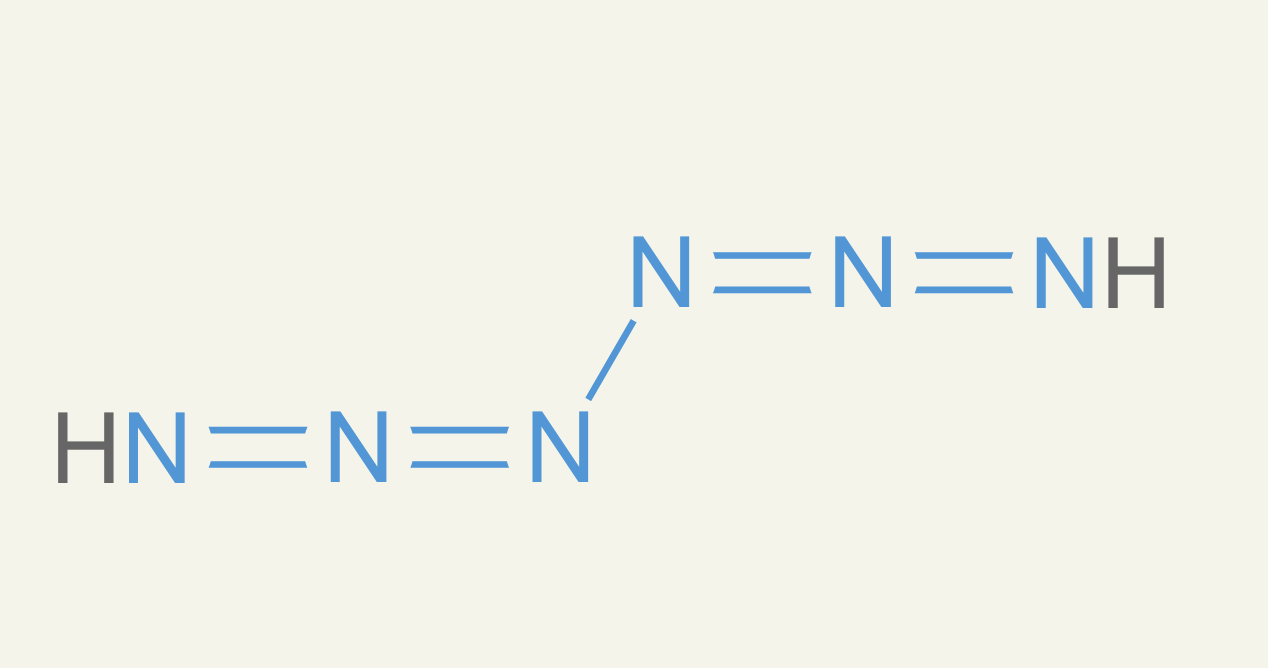
In the ether0 project, I would complain about hydrazine, especially when there were more than two nitrogens. I said they were physically impossible. Funnily enough, a paper came out in Nature a week ago announcing the first synthesis of six nitrogens in a chain. So it wasn't physically impossible anymore, I guess.4
So, we had to come up with some way to adjust our reward function to only allow "reasonable" molecules. The first thing I did was grab "structure alerts," which are lists of patterns that researchers have developed over the years that are used to exclude compounds from early drug discovery campaigns. These rules serve multiple purposes: removing likely false positives from high-throughput screening, removing groups that are known to be reactive with proteins/endogoneous compounds, removing compounds that will be problematic to develop further because they are too large, etc.
I tried a few of these lists from pharmaceutical companies. We didn't even train. They just aren't comprehensive enough, once you start to test some molecules. They don't have a long peroxide filter, they don't check for chains of thiols. Just no sane person would propose such a compound, so they aren't on the alert list.
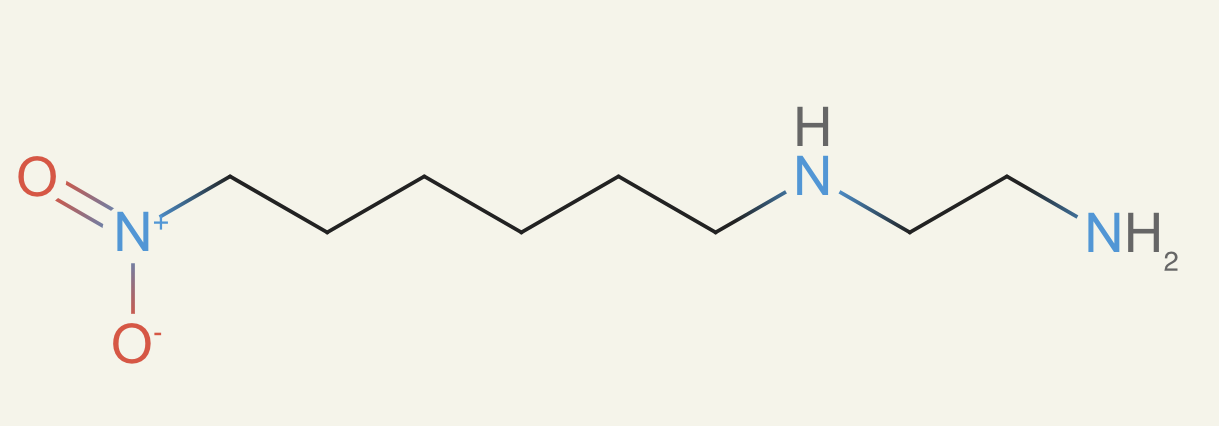
Thus I tried to build my own list. I took all compounds that have ever been synthesized and reported in ChEMBL, which tracks compounds related to drug discovery. I broke them up into every three-atom-radius subgraph (atoms one or two bonds away plus central starting atom). Then I stored the set of all those subgraphs from all the compounds in a bloom filter. Then whenever ether0 proposed a compound, we check that every three-atom-radius subgraph appears in that set. This was done as part of the reward function. Here's an example of a molecule from this:
This was awesome - it immediately learned to be more reasonable in its proposals. We worried about ChEMBL being too narrow, so we then expanded to include COCONUT, which contains nearly all known compounds isolated from organisms on Earth or found in the ocean/soil.
Then another problem cropped up: rings. Rings are a key components to drugs because they give them shapes. Nearly all small molecule drugs have rings, usually multiple. But not all rings structures can be made. There are constraints from quantum effects like Hueckel's rule, ring strain making certain sizes too unstable, and then some are just inaccessible due to the difficulty of the reactions. Here's an example of a disgusting ring proposed during training:
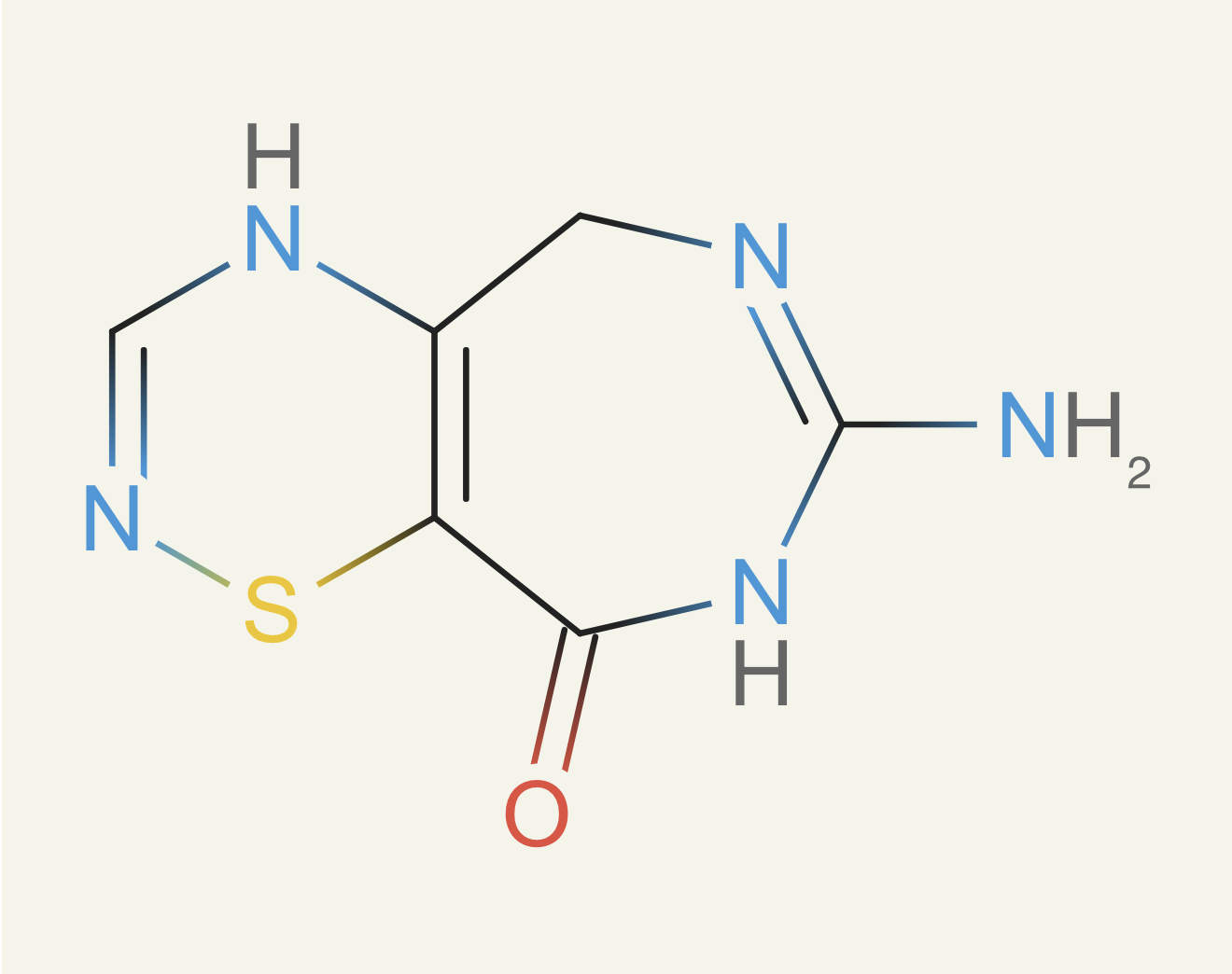
We took a page from Pat Walter's nice blog post about isolating rings. We then did the same trick as above: we took all compounds we thought were feasible, cut them down to their rings, and then stored them in a bloom filter. Then when ether0 proposed a new compound, we checked both the three-atom radius subgraphs and its rings for feasibility.
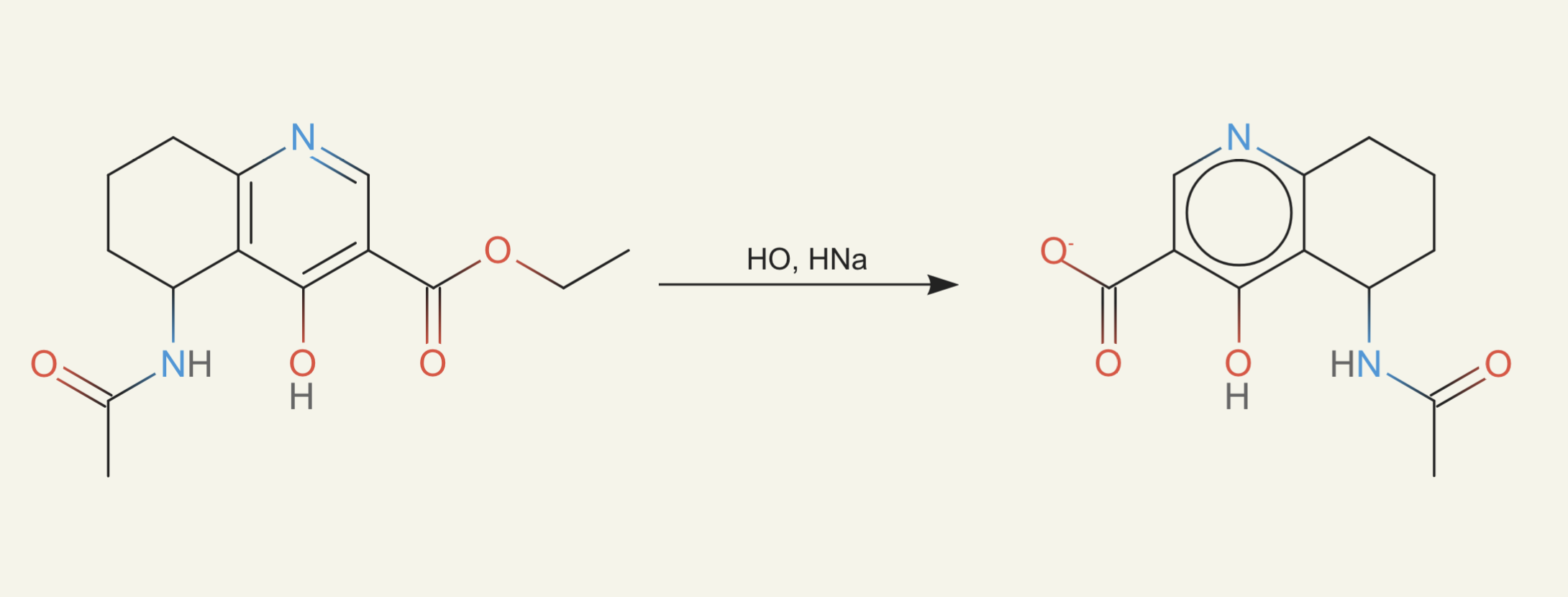
This got us to much better molecules. They had plausible rings, no weird subgroups like peroxides, and they had the correct number of atoms. Then we launched our final training run. It was going great, and then I started to look at more of the compounds. I started to notice a lot of nitro groups - the model really enjoyed them:
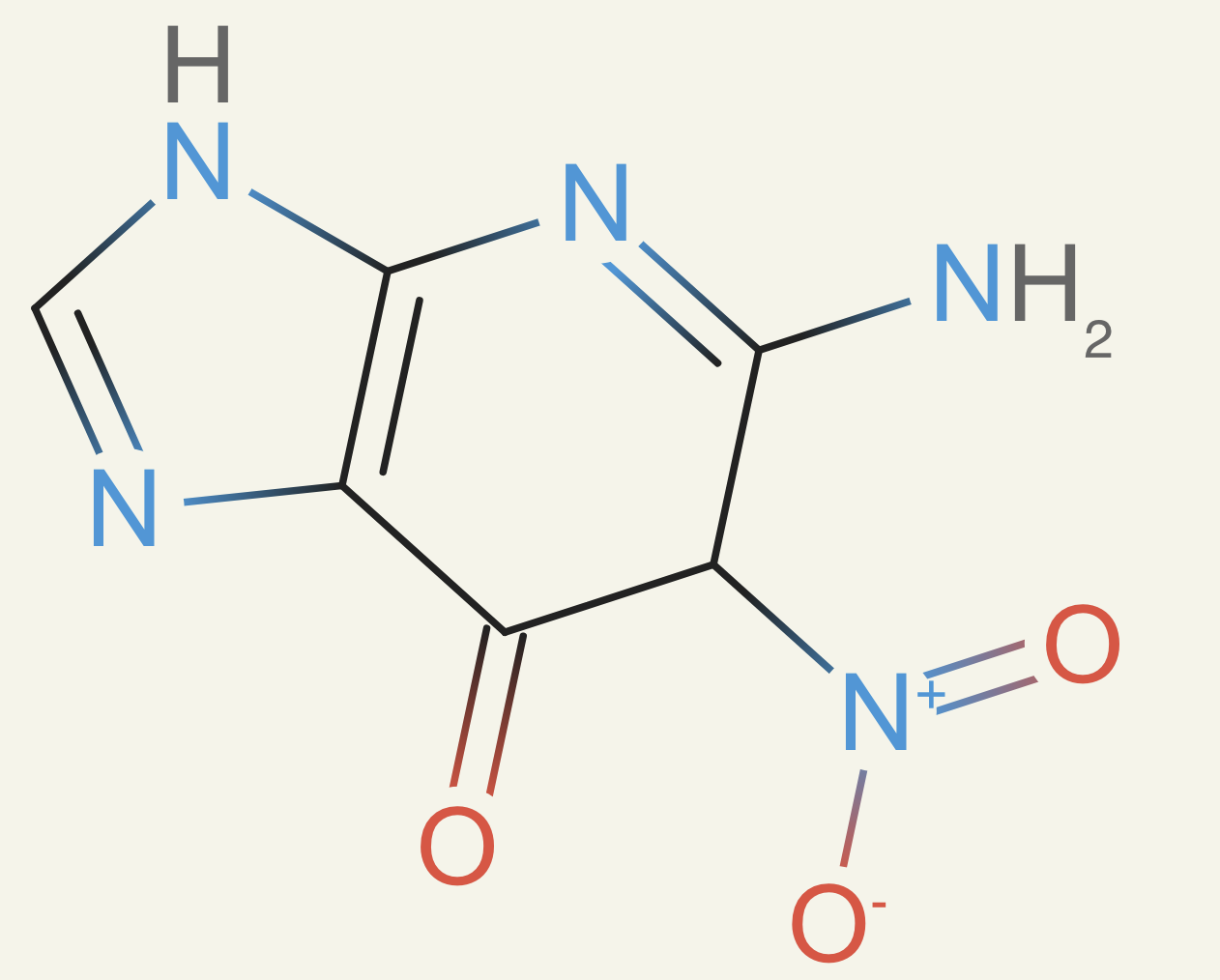
We were back in a spot like the retrosynthesis. Nitro groups are somewhat problematic, but it's a matter of preference for what I want to see in a molecule. Nitros are seen in antibiotics, but are otherwise avoided in medicinal chemistry. They cause DNA mutation and are generally reactive, causing unintended interactions. Since we kept seeing a problem with preferences now (here and above in retrosyntheses), we decided to try adding a preference tuning step.
We followed the standard playbook for RLHF and first built a reward model. I took the dataset from the molskill paper on preferences for molecules.5 These were finely-graded preferences - all the molecules considered were drug-like molecules. So there were not too many nitros in the pairs. Thus, I also built a dataset of modified drug-like molecules that violated some number of patterns I came up with: nitros, very long saturated alkyl chains, thionitrates, peroxides, etc.
Of course, we could have just computed those specific patterns directly in our reward function, but we wanted to solve the general problem of incorporating preferences into GRPO reinforcement learning. We tried reward models from base LLMs, classifiers from base LLMs, graph neural network reward models, pre-trained chemistry LLMs trained to be reward models, and more. Ultimately, we found it very hard to measure the effect downstream. We could validate the reward models, but when included in the training, we didn't get a strong enough signal to justify including them.
This was a learning process. If we don't like nitros, don't be fancy. Just add a bonus for the preference rather than be fancy. So, we decided on just a bonus to the reward function. If the molecule follows the rules and was correct, it gets a bonus. This changes the training dynamics a bit - now if all members of a GRPO group get the answer right, you get some signal from following the rules. This had the desired effect of pushing the model to get the reward correct, and prefer to get the bonus. We couldn't just always get the bonus though, because sometimes it's impossible (e.g., we require a nitro group to solve the problem) or it makes the problem much more difficult.
Here's a final example of ether0 making a molecule with formula C12H18O3N2S:
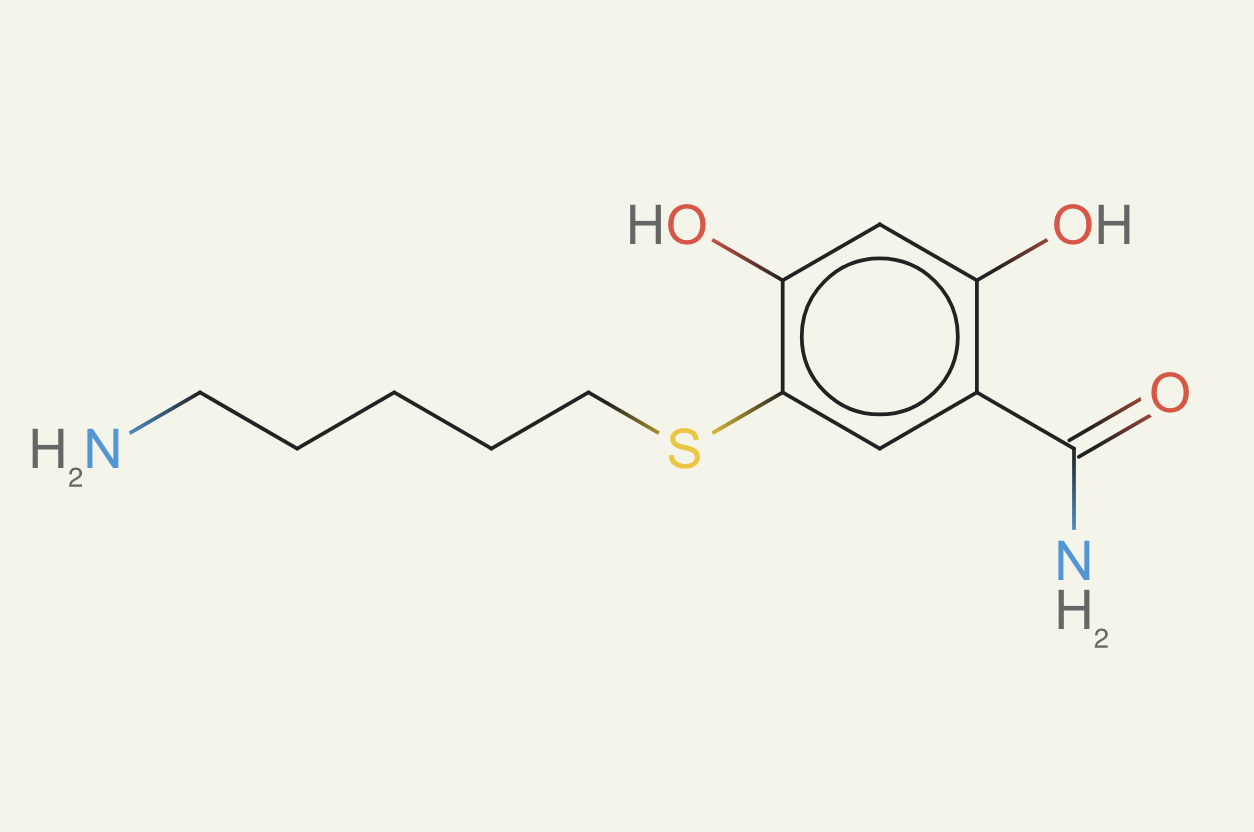
nice
reflections
This project took us about 4 months. A lot of that time was spent on these experiments, especially because the cycle time was long. It took a while to see how ether0 would hack our reward each time. Of course, training reasoning models is also not easy - see our paper to see the many small technical innovations we had to make to get reasoning models to work well in chemistry.1
I got better at anticipating these reward hacks as the project went on. You must have a more black-hat/red-teaming perspective to write good reward functions. We didn't have that perspective yet; most of our previous experience with LLMs was in fine-tuning. Now we're smarter. I think.
This was also very exciting for us: ether0 always found a way to improve. I was afraid our reward functions would be too difficult or too noisy. We had some runs where the model trained for 50 steps before getting a single problem correct, and then slowly learn it.
Thus, specifying good reward functions may now be the majority of the effort. That is great for domain experts. Maybe not so great for the frontier models pushing the domain-expertise agnostic approach. I'm sure they'll solve this (they always do) but I do think the artifact most valuable for continuing to advance AI will now be the reward function instead human preferences or large pretraining data.
conclusion
The retrosynthesis and molecule generation reward functions, which took a lot of effort, are free and open source. I believe the "reasonable" molecule check in particular, will be very valuable for those training any generative models in chemistry. It's an extremely performant measure of plausibility of an arbitrary molecules. The purchasability bloom filters are also useful, but were described in an early paper.3
This story only covered two of the tasks! They were the most interesting, but we had many iterations on the other 15 tasks as well. You can learn more about them and the broader effort for training ether0:
- Our blog post
- The manuscript
- The reward function repo
- An article in Nature about ether0
- An recent blog post by me about reasoning models
Footnotes
-
Narayanan, Siddharth M. and Braza, James D. and Griffiths, Ryan-Rhys and Bou, Albert and Wellawatte, Geemi P. and Caldas Ramos, Mayk and Mitchener, Ludovico and Rodriques, Samuel G. and White, Andrew D. "Training a Scientific Reasoning Model for Chemistry" preprint ↩ ↩2
-
Schwaller, Philippe, Teodoro Laino, Théophile Gaudin, Peter Bolgar, Christopher A. Hunter, Costas Bekas, and Alpha A. Lee. "Molecular transformer: a model for uncertainty-calibrated chemical reaction prediction." DOI:10.1021/acscentsci.9b00576 ↩
-
Jorge Medina & Andrew D. White. "Bloom filters for molecules." DOI: 10.1186/s13321-023-00765-1 ↩ ↩2
-
Weiyu Qian (钱伟煜), Artur Mardyukov & Peter R. Schreiner. "Preparation of a neutral nitrogen allotrope hexanitrogen C2h-N6." DOI: 10.1038/s41586-025-09032-9 ↩
-
Choung, Oh-Hyeon and Vianello, Riccardo and Segler, Marwin and Stiefl, Nikolaus and Jiménez-Luna, José. "Learning chemical intuition from humans in the loop." DOI: 10.26434/chemrxiv-2023-knwnv ↩