| designation: | D2-000 |
|---|---|
| author: | andrew white |
| status: | complete |
| models considered: | 27 |
| prepared date: | February 16, 2025 |
| updated date: | February 23, 2025 |
abstract: It's been a month since the first batch of reasoning models was released. Here I check in to see what's happened since then, focusing on math evals. There is an emerging pattern of fine-tuning a small language model followed by reinforcement learning. One example showed a 1.5B models was competitive with >500B language models on math. And this can require as few as 1k examples. Here I discuss some of my notes on training recipes, frameworks, rumors, and major open questions.
reasoning models
It's been about one month since the first set of compelling reasoning papers came out, including the Deepseek r1 paper1. I wrote some early reflections on what this means for AI for Science in an earlier post. Since then, there have been about a dozen models released from individuals to frontier labs. I want to review some of the progress and emerging findings from this quick progress.
First, what is a reasoning model? I think it might be better to call these "r1-style" reasoning models since there have been large language models named as reasoning. Examples include rstar-math2, QwQ3, and the PRIME model.4
Here's the main idea: A reasoning model is a large language model that is trained to output both a chain of thought5 and a response. The chain of thought should be relatively long ( 1,000 tokens) and the reasoning should improve its performance relative to a similar-sized non-reasoning models. This is sometimes called "test-time" or "inference-time" scaling because reasoning models emit more tokens per completion and gain some performance as a result.
Let's dig in to look at some of these new models.
models
I focused specifically on models that use chain of thought reasoning and focus on math evals. I needed something standard between models, so I focused on three math evals: GSM8K6, AIME 20247, and Math 5008. To combine these into one number, I subtracted the model score from what Deepseek V39 got and then averaged that difference. The idea is that Deepseek V3 is a recent non-reasoning frontier large language model (released in December) that can be a good baseline.
There have been some great models I've omitted because they implement a more complex strategy than just a trained chain of thought. These include PRIME4, OREAL10, and rstar-math2, which all used an extra language reward models and more complex inference strategies. I also did not include models that only used RL, but no reasoning, which includes Llama-3.1-Tulu-3.1-8B11 and the Deepseek math paper12, which are quite compelling as well.
Here are the model releases over the last few weeks:
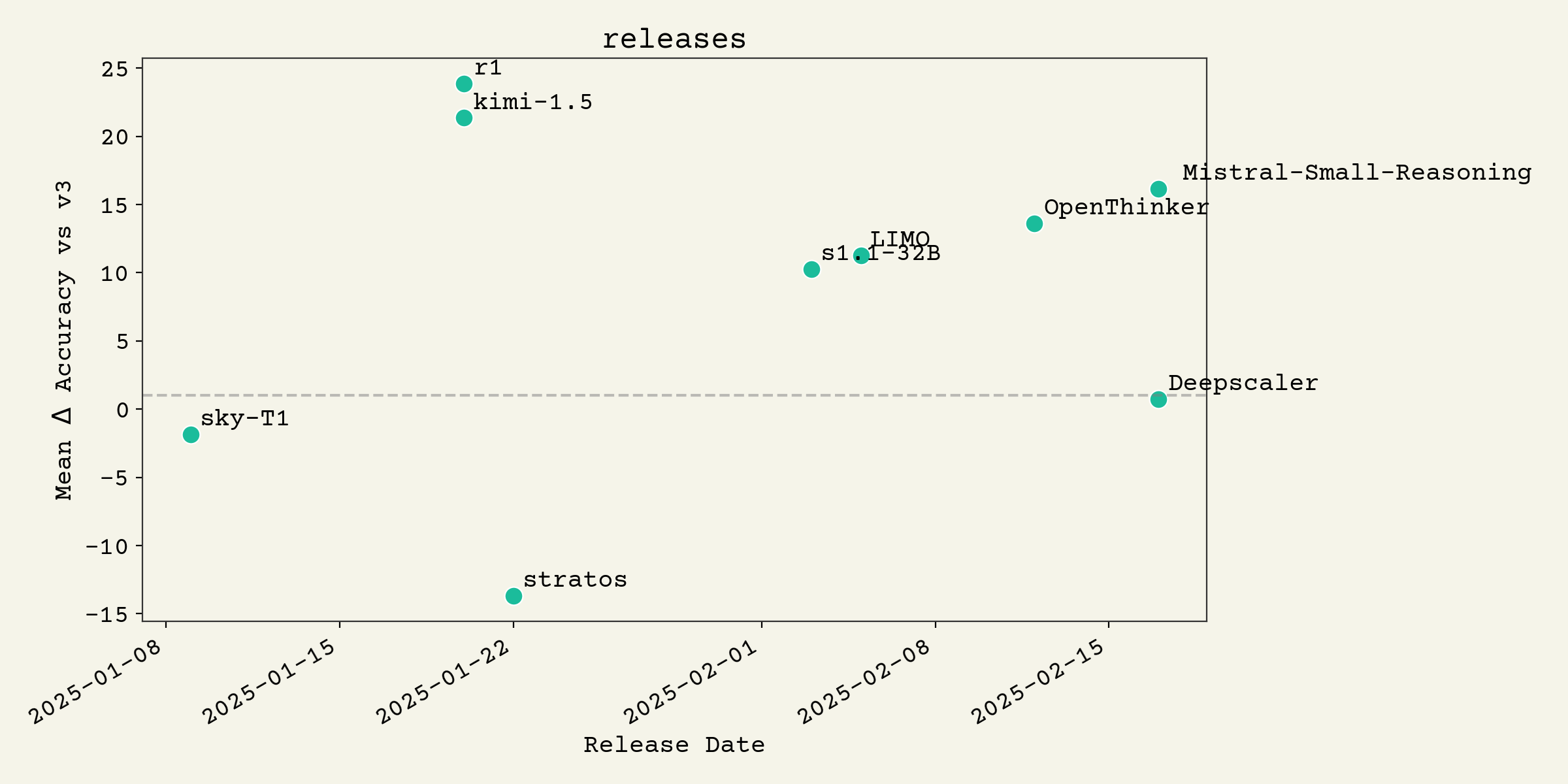
As you can see, most reasoning models are now comfortably above Deepseek V39. Of the recent ones, only Deepscaler13 used reinforcement learning. So, presumably, the other recent models could be improved further. s1.114 did use more interesting inference time strategies and LIMO15 was more about pushing the training data lower, under 1,000 examples.
state
Let's start by looking at a variety of reasoning models that came out recently to see how things are going. These are contemporary language models broken by if they use reasoning and their math eval scores.
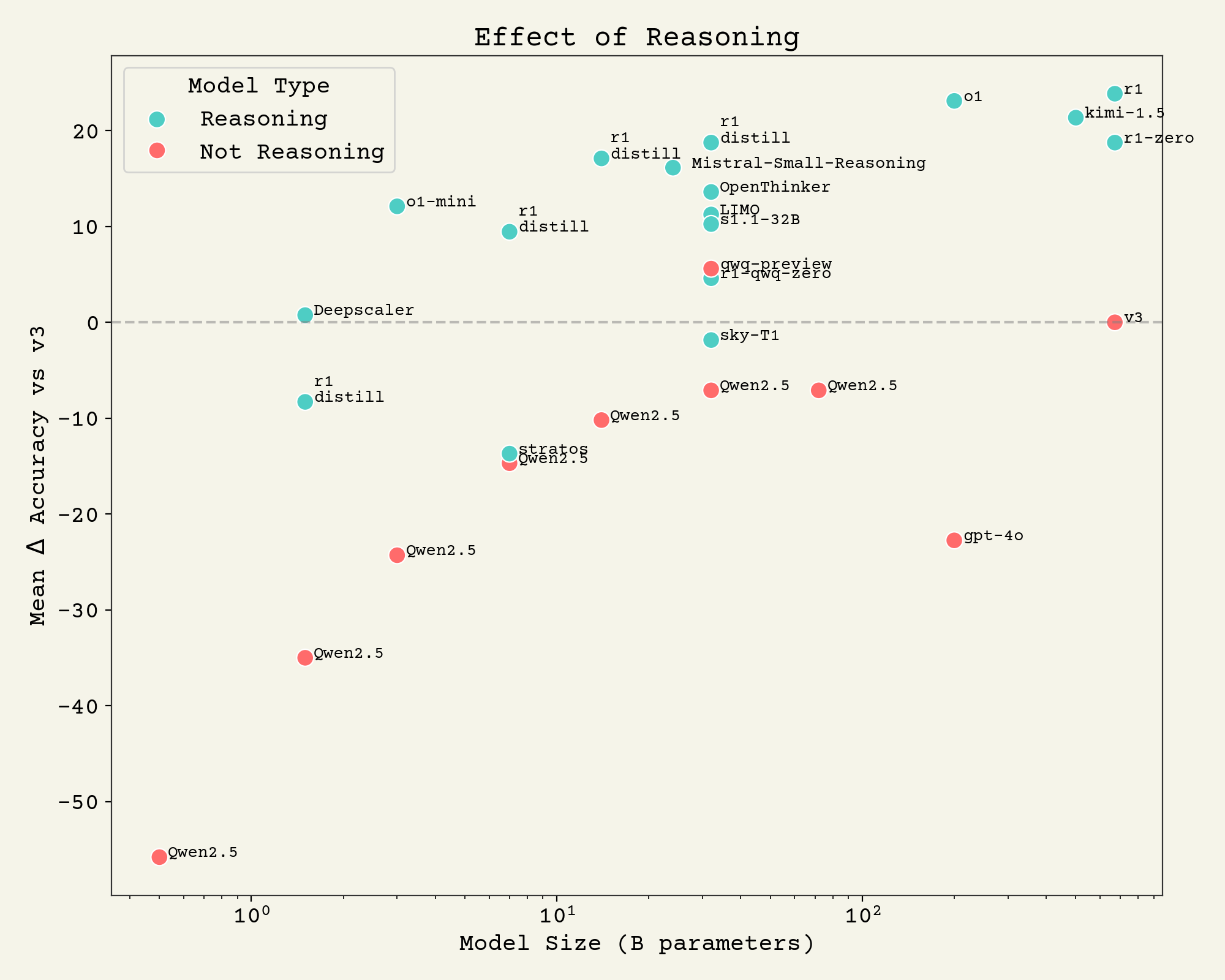
As you can see - we're seeing huge improvements on math benchmarks equivalent to huge increases of model parameter size. And these gains are almost for free, because the data required is orders of magnitude less than pre-training and the compute requirements are pretty modest. I think we've seen enough to say that r1-style reasoning improves language models.
making reasoning models
There are now three recipes for making reasoning models. They are:
-
Start from a base language model and use reinforcement learning (RL) on verifier rewards, typically with GRPO or PPO method. Statements from Skylabs and Deepseek indicate this method only works from very large models (greater than 32B). This is called a cold start. Examples include the r1-zero model1 and the SkyLabs-T1 model16.
-
Take reasoning traces17 (outputs from an existing reasoning model) and fine-tune (SFT) an instruct language model on these traces. There seems to be no lower limit on the model size, although gains seems to be largest at 1-14B parameter models. This results in a distilled reasoning model. Examples include the s1.1 model14 and the stratos model.18
-
Take a distilled reasoning model (from recipe 2) and use reinforcement learning on verifier rewards to improve its accuracy further. This provides further gains.
Here's a plot showing recipe 3 vs recipe 1:
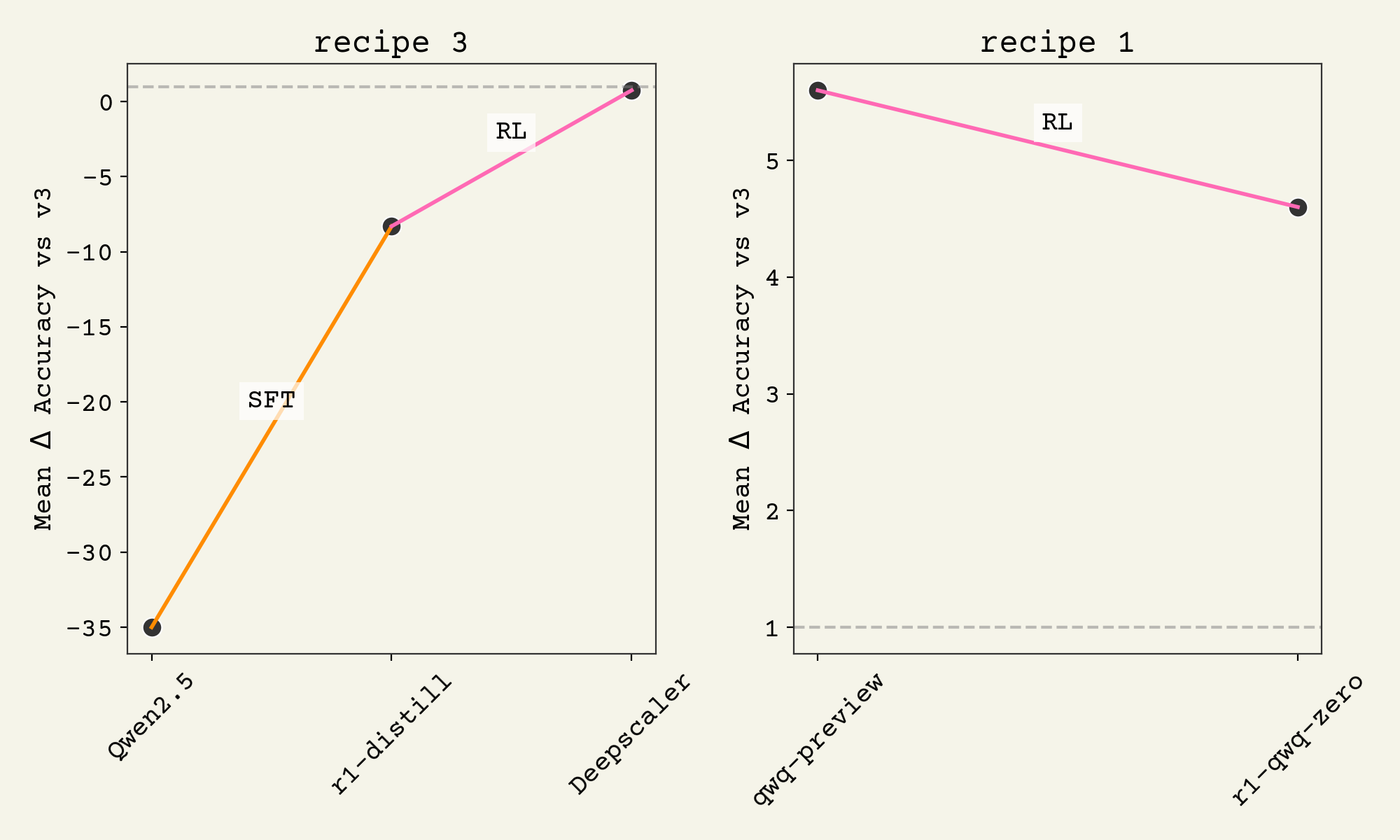
In the first example, we do recipe 3: SFT on reasoning traces and then RL with rewards on math problems. This takes a 1.5B parameter model all the way up to matching Deepseek V3, a 671B parameter model9.
The second example shows the pitfalls of recipe 1. There, a 32B model starts with RL immediately and sees a decrease in performance. Recipe 1 seems to require a larger or more capable starting model. This effect was noted by both SkyLabs group and Deepseek group, although in-person I've heard people dispute this.
Recipe 2 is the most popular, and requires relatively small amounts of data and compute. However, recent work is showing that this is suboptimal and you should always to the RL afterwards.19
infrastructure
There are a few training frameworks/libraries I've seen for implementing the recipes above. Things are moving quickly, but here's what I've seen:
-
TRL/OpenR1 from HuggingFace - they're focused on both SFT and the RL approach so they support the complete process. If you match their example scripts closely (which are focused on math), it's pretty easy to get going. However, the stack they're using is very complex between transformers, deepspeed, TRL, and their chat templating system. It can be difficult to understand how to modify the methods. This is improving as the community grows, but it's definitely a complicated and fast-moving stack.
-
verl from ByteDance - this is simpler framework that does PPO with Ray very well. They've modified the PPO to be like GRPO, but some of the nomenclature is off because it's more of a patched PPO. verl is quite extensible though and most groups using it start with a fork, rather than try to configure it.
-
OpenInstruct - this code from AI2 is based on OpenRLHF code, adapted to use GRPO instead of PPO. I've not used it, but AI2 did report using it for their Tulu-3.1 8B model with good results.11
I've used both verl and found TRL to be easier to get started. I've seen more papers come out from verl, but I've not yet seen a larger model >14B and I've had trouble getting one working. Anyway, I think this is still in flux and probably things will get a bit better soon.
thoughts are fungible
One of the most remarkable outcomes from these work is how intrinsically valuable the reasoning traces are. They're like a power-up mushroom for normal base models, providing huge gains from just a little fine-tuning. Here's a plot showing the gain from fine-tuning on reasoning traces at a variety of model sizes from the r1 paper1:
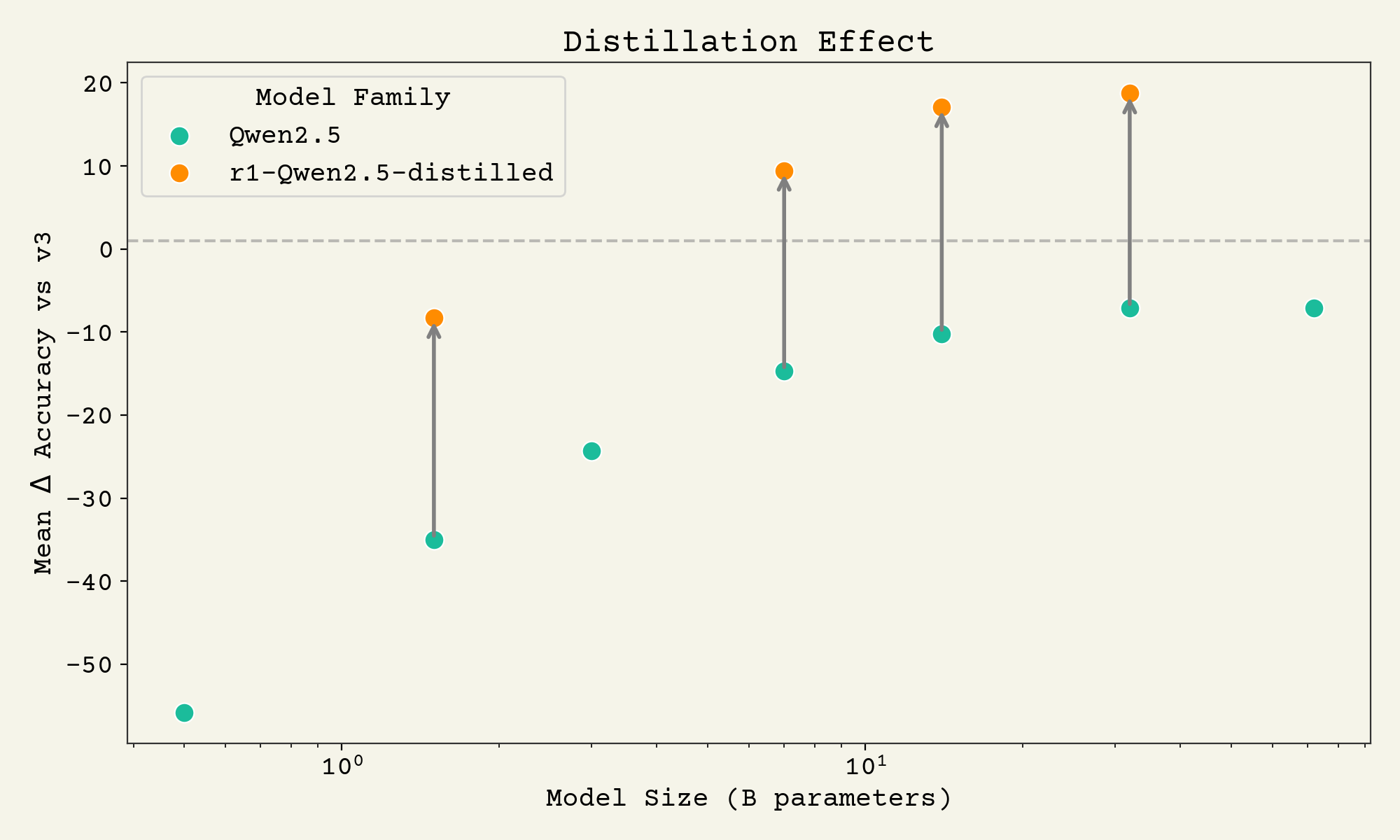
In fact, in the LIMO paper15 they showed you can get these gains from less than 1,000 of these reasoning traces. This means for <$100 of GPU compute you can distill reasoning traces from a highly capable model into a small language model. This is likely the reason that frontier labs like OpenAI and xAI do not reveal the reasoning thoughts from their models.
The broad utility of reasoning traces has also made them quite a commodity. Huggingface is accumulating many reasoning traces and going forward they will be a key ingredient for both small models and warming-up reinforcement learning. A recent preprint by Yeo et al. 20 dug into a lot of the decisions that go into making good reasoning traces and how they affect the subsequent SFT.
Early evals also show that the reasoning traces are actually faithful - representing the path the model takes to get to the answer.21 This reasoning faithfulness is also passed onto distilled models.
However, some groups are pushing towards latent chains of thought, meaning the chain of thought sequence is vectors rather than specific tokens.22 This would eliminate the ability to inspect and share reasoning traces between models, at the benefit of some gain in performance. So it's unclear how long these reasoning traces will remain relevant, if latent chains of thought are the future.
open questions
The major open questions I wonder about are:
- how far does this generalize beyond math?
- can you bootstrap from reasoning traces on simple problems and RL to hard ones?
- have we truly decoupled model knowledge from model reasoning with these small reasoning language models?
A major limitation of this analysis, and the topic of reasoning models, is almost all effort has been put into math. Math seems amenable to reasoning. Intuitively, scaling "knowledge" is less important than scaling "reasoning" with math. And we see that empirically with much larger gains on math. For example, adding reasoning to Deepseek V3 to Deepseek r11 has a 40 point gain on the math eval AIME 20247 and 30 on math eval CNMO.23 In contrast, r11 gets a 2 point gain on MMLU and a 12 point gain on GPQA-diamond which are both not math evals.
Much of the open source work has been relying on strong models providing the reasoning traces, thus supposing the existence of strong models already. Do we need the RL alone recipe above, which requires ~70B parameter language models, or can we somehow jump start the process in smaller models. It's also an open question of difficulty extrapolation. Can we get simple reasoning traces and then bootstrap to harder problems with RL? These are still unanswered in my mind.
Lastly, some of the models have unreal performance. The Deepscaler-1.5B model13 is supposedly better at math than Deepseek's V39 - about a 500x larger language model. What are the boundaries of Deepscaler? Does it really hold up with user-generated math problems? If this result holds, we've flipped the narrative on AI models. Now you can have specialized small models that are equal to very large models.
A holy grail of large language models over the last few years is how to decouple model size from reasoning. How do you strip out the parameters wasted on memorization of knowledge and only keep the reasoning parameters? We might be there with these very small and performant models. We may soon see a revitalization of retrieval-augmented generative methods where the model knowledge is stored in a database and the reasoning is stored in the weights.
rumors
Here are some of the current rumors being discussed, that will likely turn into preprints soon:
-
KL-penalty in GRPO can be eliminated.24 GRPO was the method for RL in r1 paper. GRPO is similar to PPO, except real rewards are calculated and converted to an advantage estimate. If the KL term is removed, this would make GRPO very close to REINFORCE and remove the need for a reference model, further speeding up/reducing memory of RL. Some have been arguing already with strong evidence to switch from PPO to REINFORCE.25
-
Forward vs Reverse KL formulation matters.26 GRPO uses an unusual formulation of KL divergence, which is there to regularize the model and avoid training collapse. There is speculation that the formulation being used requires a much stronger reference model, causing problems with smaller model training runs (or smaller batch sizes).
-
You can fake reasoning traces. Various ideas are floating around that you can bootstrap reasoning traces by knowing the answer and then trying to get other models to fill in the reasoning traces. Some of this was explored by Yeo et. al,20 but it's still unknown in my opinion. This would be significant because it gets us free from requiring a model that already can solve some non-zero fraction of the problems.
conclusions
So here we are - about 30 days post r1. The Deepseek r11 and Kimi papers27 didn't release their training code, but there are now multiple open source implementations for training reasoning models. None at the same scale of models as Kimi or r1 yet though. More work needs to be done and I've yet to see a mixture-of-experts model trained with RL yet. The excitement about r1-zero1, a purely RLed model, has faded and the excitement is around small models that start with fine-tuning on reasoning traces followed by RL.
We are just starting to see an open source revolution in reasoning models. It's unclear how far this will extend beyond math, but I hope it does.
Footnotes
-
Guo, Daya, et al. "Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning." arXiv preprint arXiv:2501.12948 (2025). https://arxiv.org/abs/2501.12948 ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7
-
Guan, Xinyu, et al. "rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking." arXiv preprint arXiv:2501.04519 (2025). https://arxiv.org/abs/2501.04519 ↩ ↩2
-
QwQ-preview https://qwenlm.github.io/blog/qwq-32b-preview/ ↩
-
Cui, Ganqu, et al. "Process reinforcement through implicit rewards." arXiv preprint arXiv:2502.01456 (2025). https://arxiv.org/abs/2502.01456 ↩ ↩2
-
Chain of thought is abbreviated as CoT and called "cot" (like a nap cot) when spoken. Kind of fun to say. ↩
-
Cobbe, Karl, et al. "Training verifiers to solve math word problems." arXiv preprint arXiv:2110.14168 (2021). https://arxiv.org/abs/2110.14168 ↩
-
AIME 2024: https://artofproblemsolving.com/wiki/index.php/American_Invitational_Mathematics_Examination ↩ ↩2
-
MATH 500: http://math500.com/ ↩
-
Liu, Aixin, et al. "Deepseek-v3 technical report." arXiv preprint arXiv:2412.19437 (2024). https://arxiv.org/abs/2412.19437v1 ↩ ↩2 ↩3 ↩4
-
Lyu, Chengqi, et al. "Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning." arXiv preprint arXiv:2502.06781 (2025). https://arxiv.org/abs/2502.06781 ↩
-
Lambert, Nathan, et al. Tulu 3: Pushing frontiers in open language model post-training." arXiv preprint arXiv:2411.15124 (2024). https://huggingface.co/allenai/Llama-3.1-Tulu-3.1-8B ↩ ↩2
-
Shao, Zhihong, et al. "Deepseekmath: Pushing the limits of mathematical reasoning in open language models." arXiv preprint arXiv:2402.03300 (2024). https://arxiv.org/abs/2402.03300 ↩
-
Deepscaler: https://pretty-radio-b75.notion.site/DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling-RL-19681902c1468005bed8ca303013a4e2 ↩ ↩2
-
Muennighoff, Niklas, et al. "s1: Simple test-time scaling." arXiv preprint arXiv:2501.19393 (2025). https://arxiv.org/abs/2501.19393 ↩ ↩2
-
Ye, Yixin, et al. "LIMO: Less is More for Reasoning." arXiv preprint arXiv:2502.03387 (2025). https://arxiv.org/abs/2502.03387v1 ↩ ↩2
-
A reasoning trace is prompt, chain of thought, correct answer all in one. ↩
-
stratos: https://huggingface.co/bespokelabs/Bespoke-Stratos-7B ↩
-
Setlur, Amrith, et al. "Scaling Test-Time Compute Without Verification or RL is Suboptimal." arXiv preprint arXiv:2502.12118 (2025). https://arxiv.org/abs/2502.12118v2. ↩
-
Yeo, Edward, et al. "Demystifying Long Chain-of-Thought Reasoning in LLMs." arXiv preprint arXiv:2502.03373 (2025). https://arxiv.org/abs/2502.03373 ↩ ↩2
-
Chua, James, and Owain Evans. "Inference-Time-Compute: More Faithful? A Research Note." arXiv preprint arXiv:2501.08156 (2025). https://arxiv.org/abs/2501.08156 ↩
-
latent CoT models: Hao, Shibo, et al. "Training large language models to reason in a continuous latent space." arXiv preprint arXiv:2412.06769 (2024). https://arxiv.org/abs/2412.06769; Geiping, Jonas, et al. "Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach." arXiv preprint arXiv:2502.05171 (2025). https://arxiv.org/abs/2502.05171 ↩
-
CNMO: https://en.wikipedia.org/wiki/Chinese_Mathematical_Olympiad ↩
-
Ahmadian, Arash, et al. "Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms." arXiv preprint arXiv:2402.14740 (2024). https://arxiv.org/abs/2402.14740 ↩
-
Team, Kimi, et al. "Kimi k1. 5: Scaling reinforcement learning with llms." arXiv preprint arXiv:2501.12599 (2025). https://arxiv.org/abs/2501.12599v1 ↩