| designation: | D1-007 |
|---|---|
| author: | andrew white, gianni de fabritiis |
| status: | complete |
| prepared date: | January 20, 2025 |
| updated date: | January 20, 2025 |
abstract: Reasoning models are large language models that can expend extra tokens to "think through" a problem, often displaying human-like reasoning behavior like backtracking or reflecting. Recent research progress has provided multiple compelling recipes for building these models. They seem to scale far past previous models and can exceed humans in seemingly any task. This means we are no longer limited by human graders and can begin to exceed experts in many reasoning tasks across science.
AI for science with reasoning models
We're in a bit of a new renaissance of language models in the last few months with reasoning models. Benchmarks are being broken and the number of recent papers on reasoning models is blowing-up. Below I give my own rambling interpretation of these results and then reason a bit through the consequences in AI for Science -- namely, how will it change the application of AI to scientific domains.
background
I think Noam Brown and Andy Jones had a great perspective in reinforcement learning for board games a few years back that showed you can increase inference time to increase performance of models that play board-games. They showed there are trade-offs, where you can get a better return by balancing compute on training time and testing time. Here's a particularly famous plot from Andy's paper:1
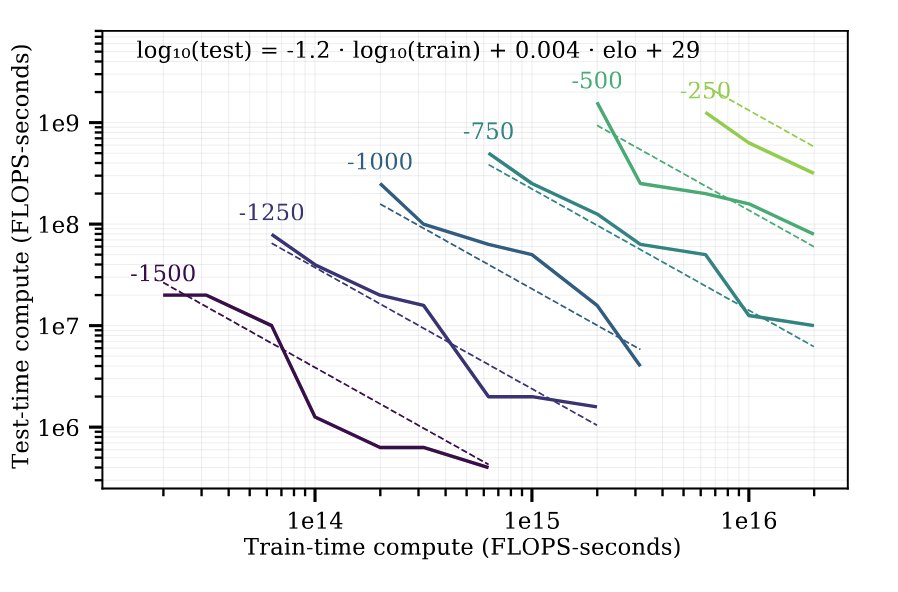
The plot shows that you can get to 1500 ELO (how good the model is) via different choices of amount of compute spent at train time or test time. Prior to late 2024, generally large language models only explored scaling training compute. More = better. This felt like a big hole was missing in the field. Could we spend more time doing inference and maybe even less time on enormous pre-training compute runs?
Noam Brown went to OpenAI and, presumably, he brought the hypothesis there and it led to reasoning language models that can expend extra reasoning tokens to do better at answering questions. This is a continuation of the original chain of thought (CoT) work,2 that showed language models do better if you prompt them to think step by step on how to answer a problem. Just like how you might get a human to do better on a word problem.3
From an outside perspective, it looks like OpenAI found a way to elicit the models to spend more inference compute on reasoning in a CoT. Those CoTs lead to improved performance on evals that require reasoning (math, code, hard STEM problems). This was o1, and it provided significant gains on many benchmarks.4
This led to series of papers trying to both reverse engineer and build similar reasoning models.5 There were a number of hypotheses about what matters - is it better search/sampling methods, is it better iterations,6 is it better scaffolding, is it new architectures, or is it new algorithms?
recipe for reasoning models
There have now been three compelling papers that showed how to build models similar or better than o1:
Here is my interpretation of the findings:
- Simple prompts and simple inference strategies work. Do many rollouts at both training time (for more correct trajectories) and inference time (for monkeys10). This is better than process reward models, Monte-Carlo Tree search, or special construction of training examples.
- Just leaving space for CoT tokens and using reinforcement learning leads to continued cycles of improvement. Challenging problems, including sparse binary outcomes, can be tackled in this way.
- The nice CoT reasoning attributes like backtracking, self-reflection, and breaking down problems emerge without prompt engineering or special algorithms, just from RL.
I think its instructive to compare the rStar paper vs the strategy in the DeepSeek paper. Here's a nice overview of how the rStar paper uses a "process preference model", which is basically a Q-value predictor, to guide a tree search algorithm for inference (the 2-shot prompt omitted):
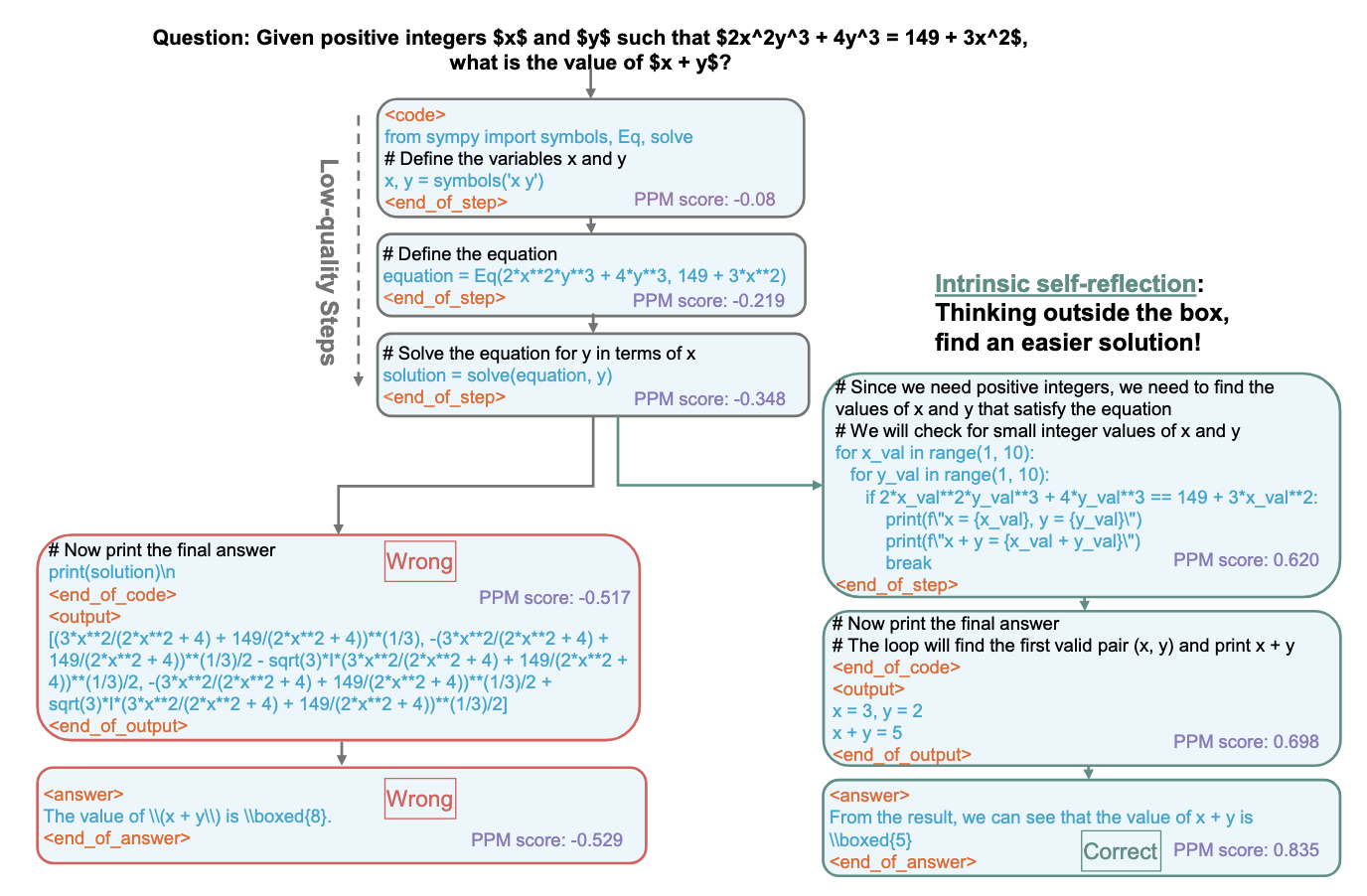
Notice how complex the strategy is. And they have two language models - the preference model and the policy/normal language model. MCTS is also not easy to batch - you have to go up and down the tree. This approach also has many hypereparamters - branching factors, depth, pruning, etc.
Now look at the r1 entire inference strategy:

It is quite nice to see that this simple strategy can work, because we (FutureHouse) found it hard to efficiently do MCTS and found multiple times that predicting Q-values is worse than just fine-tuning on successful trajectories.
To be clear, the rStar paper is not wrong or bad. In fact, it proves the point that you just need to get the successful trajectories by any means necessary. RL is probably better, since it can pick-up on small signals, but MCTS + SFT can work too.
the unknown
I think we are missing a few things from OpenAI's o1 though. From my reading of the three papers above, we still have only seen inference-time gains from majority voting/oracle verification, not really any inference-time control over reasoning amount. For example, I find it funny to consider the r1 chain of thought for the question "What is 1 + 1?"11
Wait, but maybe I should double-check. Sometimes things aren't as straightforward as they seem. For example, in binary, 1 plus 1 equals 10. But the question didn't specify a number system, so I should assume it's in the decimal system, which is the usual case unless stated otherwise.
Let me use my fingers to count. Hold up one finger on my left hand and one on my right. Now, if I put them together, that makes two fingers. Yep, that seems right.
Another way to think about it: the number that comes after 1 is 2. So adding 1 to 1 should give me the next number, which is 2. That makes sense.
I guess there's no trick here. The answer must be 2. But just to be thorough, maybe check with a simple equation. If 1 + 1 = x, then subtracting 1 from both sides gives x - 1 = 1, so x must be 2. Yep, that works.
No, wait, maybe I'm overcomplicating it. It's a fundamental math fact. Basic arithmetic. Addition of single-digit numbers. Definitely 2. Unless it's some kind of riddle where 1 + 1 equals something else, like a window or 11, but the question is straightforward, so probably just 2.
the surprising part
There has been something floating around recently in a few papers: our paper showing Llamma-3.1 7B can beat Sonnet 3.6 if trained on successful demonstrations,12 rStar-math showing a 7B model can match o1-preview in math,13 and now the DeepSeek r1 paper showing 14B models beating o1-mini across multiple benchmarks with demonstration trajectories9
Small language models can win!
Each of these papers arrived at the small language models through slightly different approaches. But the main idea is (1) get demonstration data to bootstrap learning and (2) use RL or iterative SFT to continue learning on the relevant problem. As stated in the DeepSeek paper, these gains happen at small models: "Additionally, we found that applying RL to these distilled models yields significant further gains."14 It feels like it could be a research dead-end, but it may be possible to simply build specialized small language models that can exceed frontier language models and human experts.15
Incidentally, DeepSeek released some models that already have been fine-tuned with reasoning trajectories at small sizes (e.g., 14B, 7B). I expect those can be inserted directly into an RL or iterative SFT loop to see gains on specific hard problems.
the weird part
One big question I've had is how much it matters if the reasoning CoT is "reasonable." Are they just nonsense. My null hypothesis was that the CoT is just a place to store intermediate tokens that may or may not be legible to us as reasoning. The r1-zero reasoning model showed that you can start from a non-instruct base model and start seeing accuracy gains, even though the CoT contains mixed languages, rambling paragraphs, and is illegible. So yes, they can be nonsense. It's nice to finally have some clarity on this question. And there are some interesting future directions from this that I think will shakeout over the next few months.
consequences
It has been demonstrated now in multiple papers that we can exceed human level performance on reasoning tasks purely from training. Some people have held onto a belief that post-training language models just surfaces data from pre-training. Namely, language models can only interpolate plans/reasoning patterns seen in pre-training. I think that is clearly debunked now. If you don't believe it from r1, look at our Aviary paper where we built all new problems, a new environment with new tools, and got superhuman performance even though the solutions/tools/code are not in any pre-training data.12
We can now bootstrap learning on very hard problems, providing a direct path to increasingly better models independent of how well humans do on a task. We can do rounds of sampling until we get enough good trajectories, without relying on human annotations or demonstrations. Even more important, this holds on small language models.
I believe that this changes the calculus on what is important for those working on AI. These items are seen through my lens at FutureHouse, where we're trying to build an AI Scientist for biological discoveries:
-
Challenging and meaningful problems are the most important asset. Labelers should be making hard problems, rather than annotating or "preferencing."16
-
Demonstration reasoning trajectories are fungible between models and model size, and may be more important in the long run relative to models or training data. These should be obtained via inference. They can be filtered by humans/LLMs 17
Notice that pre-training data and huge compute are not key pieces for this process. Obviously, this assumes you start with someone else's base/instruct model, but the compute can be small for these 7B/14B/32B models. Preferences, process annotations, MCTS, and specialized pre-training data are not part of the process to make strong reasoning models.18
limitations
There are a few limitations to this paradigm. One is obviously that you need a verifiable problem, which is not always easy if you're trying to predict the outcome of a laboratory experiment or an expensive simulation. It is exciting though, that you can just use a binary reward like an LLM graded or multiple-choice question response.
There are other kinds of problems that are resistant to reasoning. For example, guessing a random number. More importantly, there are real benchmarks where human experts can get good scores but language models don't get better with either size or other benchmark performance. For example, here's the results of o1 on two Lab-Bench19 tasks from the system card:20
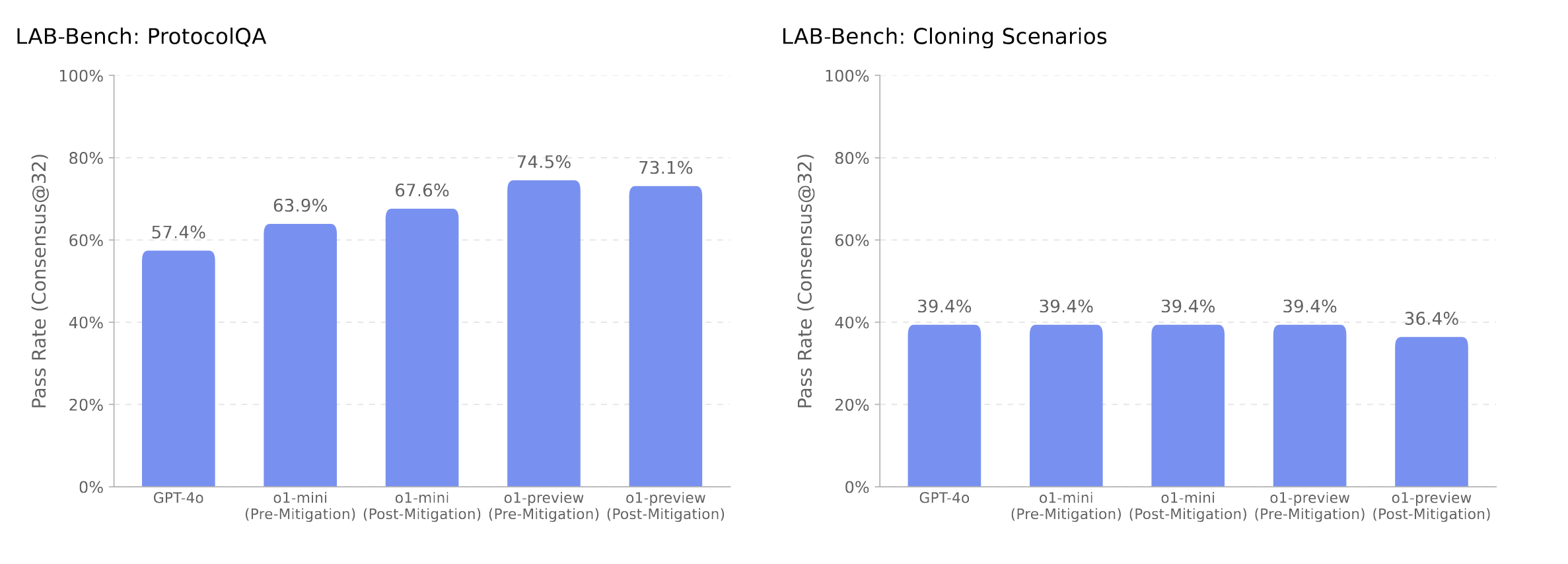
The left task, ProtocolQA, is primarily a reasoning task. It consists of lab protocols where one obvious mistake is made. It's perfect for reasoning and we see performance increase on better models. The right tasks, CloningScenarios, relies on examining multiple DNA sequences and predicting their outcomes from reactions or other transformations. It is very challenging to reason on CloningScenarios without tools or some kind of specialized DNA tokens. There is no gain with better reasoning models.
There are tasks that are actually not reasoning limited, but limited by some other attribute of the problem.
conclusions
I've felt like AI in science has fallen into two categories: (1) specialized models like RFDiffusion that can do things no human could ever attempt and are trivially superhuman at one task and (2) agents like ChemCrow21 that can string together existing tools to do reasoning tasks at scale, but with far less intelligence than a real expert. We now have some evidence that we can get to that superhuman intelligence level on reasoning tasks. It will be very interesting see what is the "Move 37 equivalent" for reasoning models in science.22
personal reflection
I used to work on protein folding. I would use molecular dynamics of proteins to predict their structures. It took a ton of compute and was hard to do. Back in my day, people had been creating ever larger molecular dynamics simulations, better accuracy force fields, and even creating custom silicon and racks for doing molecular dynamics simulations. We all thought that it was a matter of time before we could predict protein structures, but it would be on supercomputers or $100M custom machines. Instead, AlphaFold came out and made all protein folding immediately accessible to anyone with a GPU. Then, Sergey Ovchinnikov made it possible for anyone with a Google Colab account. I cannot emphasize how shocking this was to me - that protein folding was solved and it only takes a few minutes per protein. It was a cataclysmic flattening of a field dominated by supercomputer allocations and extreme compute. This was the topic of the most recent chemistry Nobel Prize awarded to the creators of AlphaFold and RosettaFold.
It's still cloudy, but we may be close to a system where you insert your environment and problem set, and you get back a small super-intelligence in that domain. Maybe that whole system is the definition of AGI, or ASI. I don't know. But it feels like we're close to the "intelligence problem" being solved as definitively as protein folding.
acknowledgements
The writing here is by me, and thus all mistakes are mine. But most of the key ideas here came from discussions with Gianni De Fabritiis, who has very good insight but likes writing papers instead of blogs. Also huge thanks to Rob Ghilduta for hosting his small SF reading group on models that think good.
Footnotes
-
These same CoTs are what reasoning models output, but the original CoT was a "hack" of frontier language models. Reasoning models are trained from the beginning with the CoT. Of course, people previously tried to make CoTs trainable with things like process supervision models (https://arxiv.org/abs/2305.20050), but I view that direction of work to be a bit of a dead-end now. ↩
-
https://arxiv.org/abs/2501.04519,https://arxiv.org/abs/2405.03553, https://arxiv.org/abs/2406.06592, https://arxiv.org/abs/2410.18982 ↩
-
https://github.com/MoonshotAI/Kimi-k1.5/blob/main/Kimi_k1.5.pdf ↩
-
https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf ↩ ↩2
-
https://arxiv.org/abs/2407.21787 and https://arxiv.org/abs/2412.21154 ↩
-
Thanks to https://x.com/teortaxesTex for highlighting this ↩
-
For example, here we beat least one task on both humans and frontier models with a small model https://arxiv.org/abs/2412.21154 ↩
-
Even better - can you find ways to generate problems that are not limited by human intelligence as the ceiling. And we may have some forgiveness too, since the rStar-math saturated a benchmark that had 10% invalid problems! ↩
-
As shown in deepseek paper (https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf), these can be cut down if you want very nice legible reasoning traces. ↩
-
Admittedly, these are necessary to make the models easy to work with. Certainly all the normal steps to make human-friendly chat models are essential. But the r1-zero result showed they are optional for correctness on a benchmark. ↩
-
https://cdn.openai.com/o1-preview-system-card-20240917.pdf ↩
-
https://en.wikipedia.org/wiki/AlphaGo_versus_Lee_Sedol#Game_2 ↩